Launch Bay
Platformer Slice Benchmark
AI benchmark
A browser platformer benchmark for comparing how different AI models build and revise a small playable slice.
Details
- Status
- Local model benchmark
- Images
- 3 images linked
Stack
Source
Benchmark
Result table
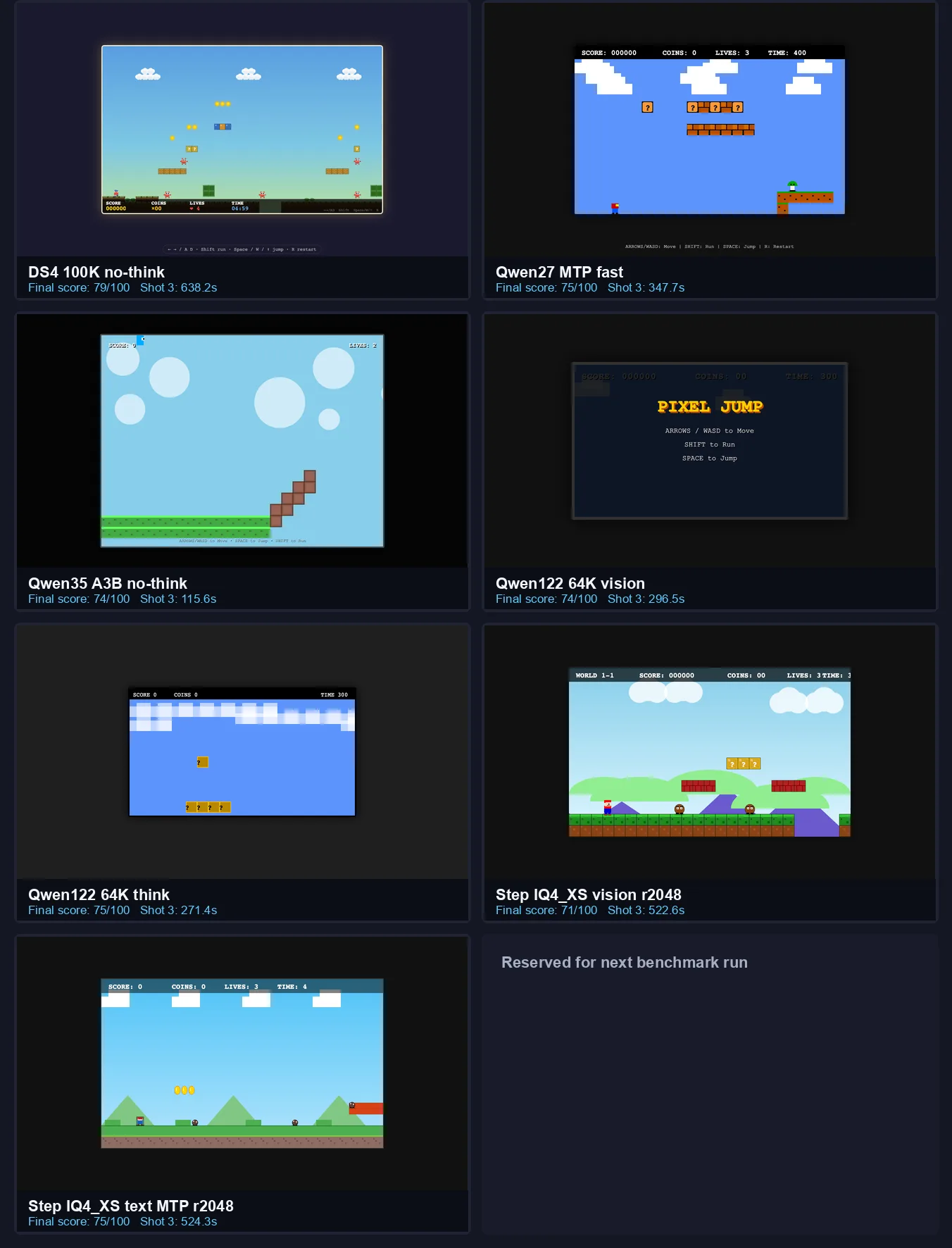
Scores are from the final benchmark shot.
| Model | Final | Shot 1 | Shot 2 | Shot 3 | Wall time |
|---|---|---|---|---|---|
| ds4-100k-nothink | 79/100 | 72 | 72 | 79 | 638.2s |
| qwen27-mtp-fast | 75/100 | 73 | 73 | 75 | 347.7s |
| qwen122-q4xl-vision-64k-think | 75/100 | 67 | 68 | 75 | 271.4s |
| step37-unsloth-iq4xs-text-mtp2-r2048 | 75/100 | 66 | 74 | 75 | 524.3s |
| qwen35-a3b-no-think | 74/100 | 47 | 67 | 74 | 115.6s |
| qwen122-q4xl-vision-64k | 74/100 | 71 | 71 | 74 | 296.5s |
| nex-n2-mini-q8-vision-64k | 74/100 | 64 | 63 | 74 | 222.7s |
| step37-unsloth-iq4xs-vision-r2048 | 71/100 | 62 | 68 | 71 | 522.6s |
Playable Builds
Load a benchmark run
Sandboxed browser builds from the final benchmark shots.
Screenshots
Images from the project
Some are current captures; some are concept images or source art.
Cropped benchmark contact sheet comparing final outputs from local and AI model runs.
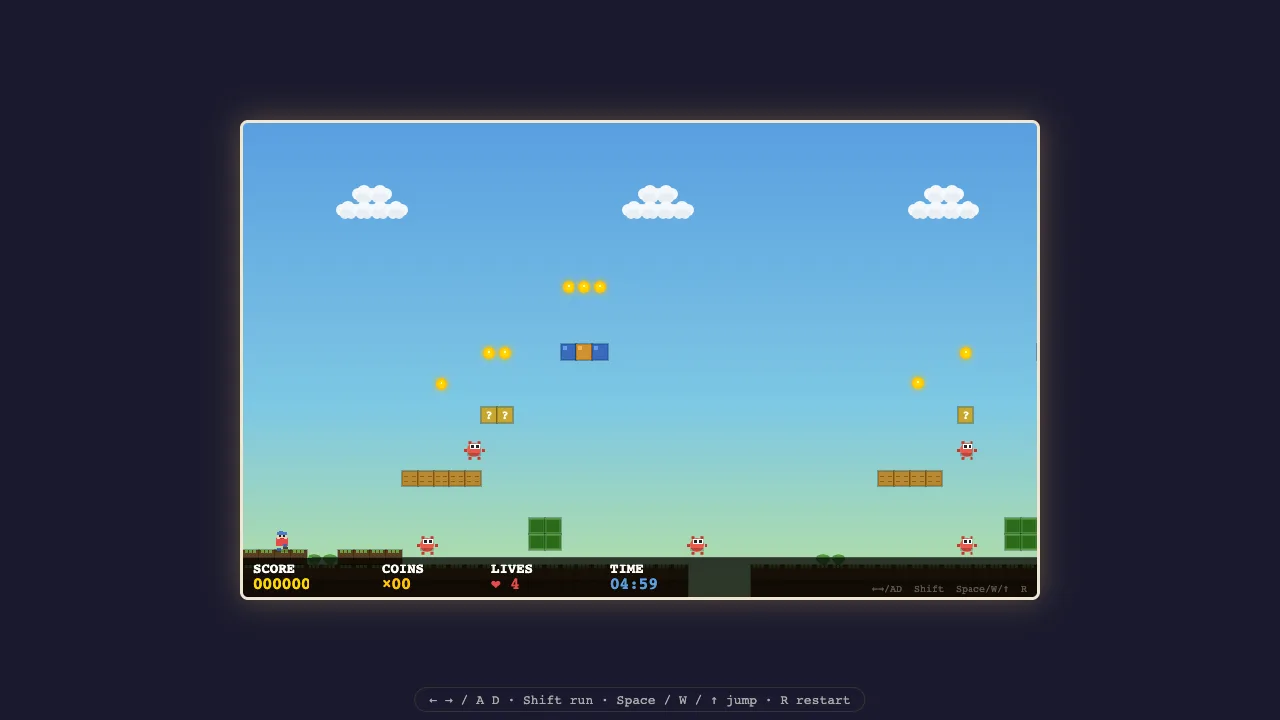
Playtest capture from the top-scoring DS4 run after automated movement input.
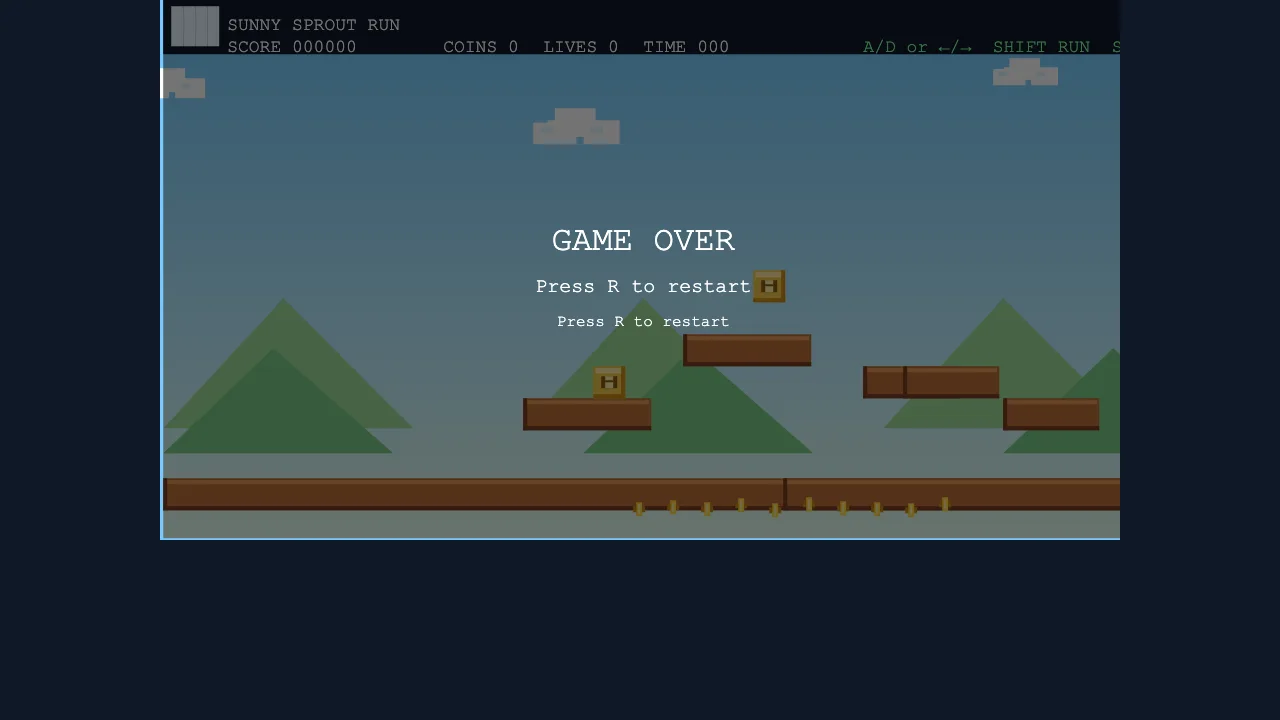
Playtest capture from the Nex run after automated movement input.
Overview
This benchmark asks several models to build and revise the same small browser platformer slice, then compares the final playable output.
Now
The current page publishes the June benchmark results, selected playtest captures, and a cropped contact sheet of final outputs.
Why I'm making it
Small playable tests make model differences easier to see than chat transcripts: movement, layout, errors, and polish all show up on screen.